

一文解构海康文搜CVR
一文解构海康文搜CVR
在传统安防系统中,视频检索依赖时间、通道、报警事件等有限条件,效率低、操作繁琐,难以满足日益增长的海量数据管理需求。
海康威视文搜CVR,基于流直存+多模态大模型技术,实现以文搜图、以图搜图,彻底打破传统CVR存储模式,推动智能安防进入“语义级检索”时代。

本文将深入解析海康文搜CVR711XPro系列的核心能力、技术优势与应用场景等方面,带您全面了解这一智能视频存储设备的革新之作。
核心技术:流直存+多模态大模型
文搜CVR的底层技术架构是其高效性能的保障,采用两大核心技术:
1. 流直存技术
视频流直接写入存储设备,无需额外服务器中转,降低系统复杂度与成本,同时保障数据完整性与实时性。
2. 多模态大模型
基于深度学习的大模型,具备强大的开放语义理解能力,能识别:
人物特征(衣着颜色、性别、年龄段…)
车辆类型(车牌、颜色、车型、品牌…)
行为描述(抽烟、拿包、推车…)
非机动车、物品等通用目标
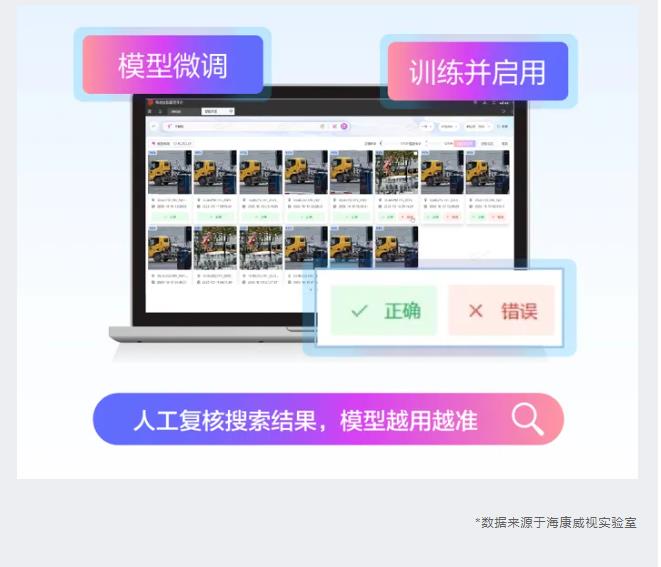
相比传统依赖预设规则的CV算法(准确率60%~75%),文搜CVR的目标识别准确率高达90%以上,且支持文本微调,越用越准。

{kind=link}
{kind=link}